pandasの使い方
ライブラリの使い方
>
Python
- 1.pandasを動かしてみる
- 2.pandasのデータ構造
- 2.1.pandasの構造取得
- 2.2.Seriesの構造と作成
- 2.3.DataFrameの構造と作成
2.4.dataの操作
2.5.indexの操作
2.6.columunsの操作
3.データの読み書き
2.3.DataFrameの構造と作成
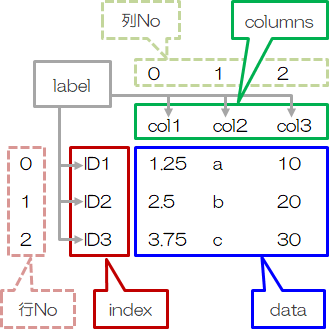
DataFrameは二次配列を表現するデータの集合体です。
pandas.DataFrame( data = None, index = None, columns = None, dtype = None, name = None
copy = False )
| 引数 | 概要 |
|---|---|
| data | 格納するデータを指定します(下図青枠)。 |
| index |
data行一つ一つに対応するlabelを指定します(下図赤枠)。
指定しない場合は連番[0, 1, 2, …]が自動的に入ります。 |
| columns |
data列一つ一つに対応するlabelを指定します(下図緑枠)。
指定しない場合は連番[0, 1, 2, …]が自動的に入ります。 |
| dtype |
指定したdata(下図青枠)のデータ型(int, float, str等)を指定します。
指定しない場合は、dataから自動的に設定されます (dataに文字列が含まれると、数値もstr型になります)。 |
DataFrame:二次配列
行 / 列Noは自動的に付与され、0からの連番(0, 1, 2, …)になります。DataFrameを新規に作成する場合、dataには次のいずれかを用います。
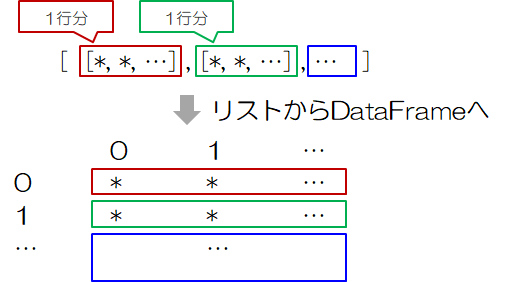
- リスト(Python標準) :[[*, *, …], [*, *, …], …]
- タプル(Python標準) :((*, *, …), (*, *, …), …)
- Dictionary(Python標準) :{ 'x':[*, *, …], 'y':[*, *, …], …}
- 二次元のndarray(Numpy配列) :array( [[*, *, …], [*, *, …], …] )
- Series(pandas) :[ser1, ser2, …](2.2節参照)
(1)dataの定義
a)リスト、タプル、二次元Numpy配列
pandasをpdで表すとして(import pandas as pd)、
pd.DataFrame( *** ) または pd.DataFrame( data = *** )
*** = [[*, *, …], [*, *, …], …]
or
((*, *, …), (*, *, …), …)
or
np.array( [[*, *, …], [*, *, …], …] )
“data =”は省略可能です。
*** = [[*, *, …], [*, *, …], …]
or
((*, *, …), (*, *, …), …)
or
np.array( [[*, *, …], [*, *, …], …] )
>>> pd.DataFrame( [[1, 2, 3], [4, ,5, 6]] ) #リストで指定 >>> pd.DataFrame( ((1, 2, 3), (4, 5, 6)) ) #タプルで指定 >>> pd.DataFrame( np.array([[1,2,3], [4,5,6]]) ) #Numpy配列で指定 #結果はどれも同じ 0 1 2 0 1 2 3 1 4 5 6
リスト、タプル、二次元numpy配列、Dictionaryは、変数に入れてからDataFrameを作ることもできます(むしろこちらの方が一般的)。
ls = [[*, *, …], [*, *, …], …](リストの場合)とおいて、
pd.DataFrame( ls ) または pd.DataFrame( data = ls )
pd.DataFrame( ls ) または pd.DataFrame( data = ls )
>>> ls = [[1, 2, 3], [4, 5, 6]] #例えばリストの場合 >>> pd.DataFrame( ls ) 0 1 2 0 1 2 3 1 4 5 6
b)Dictionary
keyは、columnsラベルとして同時に設定されます。 この場合、行方向と列方向を意識しておく必要があります。
pd.DataFrame( data = { 'x' : [*, *, …], 'y' : [*, *, …], … } )
変数を使って指定する場合は次のようにします。
dic = { 'x' : [*, *, …], 'y' : [*, *, …], … }とおいて、
pd.DataFrame( dic ) または pd.DataFrame( data = dic )
>>> pd.DataFrame( {'a': [1, 4], 'b': [2, 5], 'c': [3, 6]} )
a b c
0 1 2 3
1 4 5 6
#もし、{'a': [1, 2, 3], 'b': [4, 5, 6]}と設定すると
>>> pd.DataFrame( {'a': [1, 2, 3], 'b': [4, 5, 6]} )
a b
0 1 4
1 2 5
2 3 6
c)Series(pandas)
1つのSeriesをDataFrame化する場合、indexはそのまま継承、nameはcolumnsラベルとして扱われます。
pd.DataFrame( ser1 )
または
pd.DataFrame( data = ser1 )
または
pd.DataFrame( data = ser1 )
>>> ser = pd.Series([1, 2, 3], index = ['a', 'b', 'c'], name = 'x') >>> ser a 1 b 2 c 3 Name: x, dtype: int64 >>> pd.DataFrame(ser) x a 1 b 2 c 3
pd.DataFrame( [ser1, ser2, …] )
または
pd.DataFrame( data = [ser1, ser2, …])
または
pd.DataFrame( data = [ser1, ser2, …])
>>> ser1 = pd.Series([1, 2, 3], index = ['a', 'b', 'c'], name = 'x') >>> ser2 = pd.Series([4, 5, 6], index = ['a', 'b', 'c'], name = 'y') >>> df = pd.DataFrame([ser1, ser2]) >>> df a b c x 1 2 3 y 4 5 6
>>> df.T x y a 1 4 b 2 5 c 3 6
>>> ser1 = pd.Series([1, 2, 3], index = ['a', 'b', 'c'], name = 'x') >>> ser3 = pd.Series([4, 5, 6], index = ['a', 'b', 'd'], name = 'y') >>> pd.DataFrame([ser1, ser3]) a b c d x 1.0 2.0 3.0 NaN y 4.0 5.0 NaN 6.0
>>> ser1 = pd.Series([1, 2, 3], index = ['a', 'b', 'c'], name = 'x') >>> ser4 = pd.Series([4, 5, 6], index = ['a', 'b', 'c'], name = 'x') >>> pd.DataFrame([ser1, ser4]) a b c x 1 2 3 x 4 5 6
(2)indexの定義
pd.DataFrame( ls, index = [*, *, …] )
pd.DataFrame( ls, index = (*, *, …) )
pd.DataFrame( ls, index = np.array([ *, *, … ]) )
pd.DataFrame( ls, index = (*, *, …) )
pd.DataFrame( ls, index = np.array([ *, *, … ]) )
>>> ID = ['a', 'b'] #リストで指定
>>> ID = ('a', 'b') #タプルで指定
>>> ID = np.array(['a','b']) #numpy配列で指定
#結果はどれも同じ
>>> pd.DataFrame( ls, index = ID )
0 1 2
a 1 2 3
b 4 5 6
indexラベルは同じ値でも、空白でも構いません。
#indexラベルが同じ値の場合 >>> pd.DataFrame( ls, index = ['a', 'a'] ) 0 1 2 a 1 2 3 a 4 5 6 #indexラベルが空白の場合 >>> pd.DataFrame(ls, index = ['', ''] ) 0 1 2 1 2 3 4 5 6
(3)columnsの定義
a)リスト、タプル、numpy配列
columnsもdata同様、リスト、タプル、numpy配列によって設定できます。
pd.DataFrame( ls, columns = [*, *, …] )
pd.DataFrame( ls, columns = (*, *, …) )
pd.DataFrame( ls, columns = np.array([ *, *, … ]) )
pd.DataFrame( ls, columns = np.array([ *, *, … ]) )
>>> col = ['x', 'y', 'z'] #リストで指定
>>> col = ('x', 'y', 'z') #タプルで指定
>>> col = np.array(['x', 'y', 'z']) #numpy配列で指定
#結果はどれも同じ
>>> ls = [[1, 2, 3], [4, 5, 6]]
>>> ID = ['a', 'b']
>>> pd.DataFrame(ls, index = ID, columns = col )
x y z
a 1 2 3
b 4 5 6
columnsもindex同様、同一ラベル、空白を許容します。
#columnsラベルが同じ値の場合 >>> pd.DataFrame(ls, index = ID, columns = ['a', 'a', 'a']) a a a a 1 2 3 b 4 5 6 #columnsラベルが空白の場合 >>> pd.DataFrame(ls, index = ID, columns = ['', '', '']) #columnsが空白のため空行 a 1 2 3 b 4 5 6
b)dataをDictionaryで定義した場合
Dictionaryでdataを定義する場合、keyはcolumnsラベルとして扱われます((1)c)参照)。dataにDictionaryを定義した上で、columnsにDictionaryのKeyと異なる値のリストを定義した場合、次のようになります。
>>> dic2d = {'a': [1, 2, 3], 'b': [4, 5, 6]}
>>> pd.DataFrame( dic2d, columns = ['x', 'b'] )
x b
0 NaN 4
1 NaN 5
2 NaN 6
>>> dic2d = {'a': [1, 2, 3], 'b': [4, 5, 6]}
>>> pd.DataFrame( dic2d, columns = ['b', 'a'] )
b a
0 4 1
1 5 2
2 6 3
(4)dtypeの定義
dataをすべて指定した同じ型に統一します。
pd.DataFrame( ls, dtype = *** )
***にはおおまかに、int(整数)、float(浮動小数点)、 complex(複素数)、str(文字列)、bool(True or False)等があります。
型を指定しない場合、データから自動で型指定されます。
#float型を指定 >>> pd.DataFrame( ls, index = ID, columns = col, dtype = float ) x y z a 1.0 2.0 3.0 b 4.0 5.0 6.0
(5)dataの型
型を指定しない場合(dtypeの指定なし)、データの中身から自動で型指定されます。#指定しない場合 → リストの中身からint型が割り当てられる >>> ls = [[1, 2, 3], [4, 5, 6]] >>> pd.DataFrame( ls, index = ID, columns = col ) x y z a 1 2 3 b 4 5 6
>>> ls2d = [ [1, 2.0, 3 ], [ 4, 5, 6] ] >>> df = pd.DataFrame( ls2d, index = ID, columns = col ) >>> df x y z a 1 2.0 3 b 4 5.0 6
リストにint型、float型、str型が含まれている場合
>>> ls2d = [ [1, 2.0, 3 ], [ 4, 5, 6] ] >>> ls2d = [[1, 2.0, 3], [4, 5, 'a']] >>> df = pd.DataFrame(ls2d, index = ID, columns = col) >>> df x y z a 1 2.0 3 b 4 5.0 a
>>> type(df.loc['a', 'z']) <class 'int'> >>> type(df.loc['b', 'z']) <class 'str'>
(6)空のDataFrame作成
空のDataFrameを作成できます。
pd.DataFrame( )
>>> pd.DataFrame() Empty DataFrame Columns: [] Index: []
pd.DataFrame( {'x':[], 'y':[]} )
>>> pd.DataFrame({'x':[],'y':[]})
Empty DataFrame
Columns: [x, y]
Index: []
pd.DataFrame( index= ID, columns = col )
または
pd.DataFrame( data = [], index= ID, columns = col )
または
pd.DataFrame( data = [], index= ID, columns = col )
>>> pd.DataFrame( data = [], index = ['a','b','c'], columns = ['x', 'y'] ) x y a NaN NaN b NaN NaN c NaN NaN
>>> pd.Series() __main__:1: DeprecationWarning: The default dtype for empty Series will be 'object' instead of 'float64' in a future version. Specify a dtype explicitly to silence this warning. Series([], dtype: float64)
(7)DataFrame作成時のエラー
a)dataサイズとindex/columnsサイズのアンマッチ
dataサイズとindex/columnsサイズが異なる場合、エラーが発生します。
dataサイズとindexサイズは合わせる必要があります。
>>> df = pd.dataFrame( [[1,2,3],[4,5,6]], index = ['a', 'b', 'c', 'd']) Traceback (most recent call last): File "", line 1, in ***** 省略 ***** AttributeError: module 'pandas' has no attribute 'dataFrame'


