pandasの使い方
ライブラリの使い方
>
Python
- 1.pandasを動かしてみる
- 2.pandasのデータ構造
- 2.1.pandasの構造取得
- 2.2.Seriesの構造と作成
- 2.3.DataFrameの構造と作成
2.4.dataの操作
2.5.indexの操作
2.6.columunsの操作
3.データの読み書き
2.pandasのデータ構造
pandasには主に次の二つのデータ構造があります。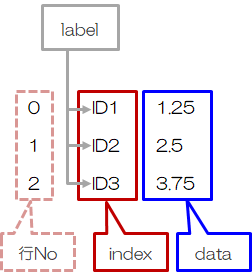
Series:一次配列
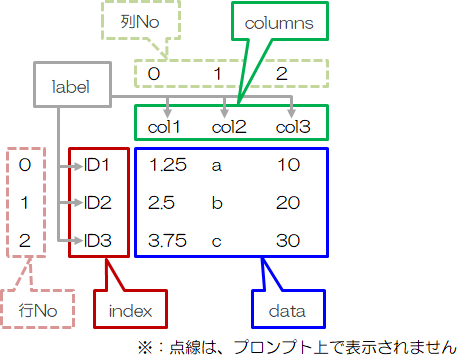
DataFrame:二次配列
indexやcolumnsは、各データにラベルをつけるもので、データを抽出する際非常に便利です (Dictionaryのkeyと同じような機能を持っています)。 従って、indexやcolumnsは定義しておくことをお勧めします。同じ配列[1, 2, 3]をSeriesとDataFrameで作ると、次のようになります。 このとき、データにラベリングをするために、indexを['a', 'b', 'c']、columnsを'x'と定義しておきます。
>>> ls = [1, 2, 3] >>> id = ['a','b','c'] #Seriesの場合(行なのか列なのか・・・?) >>> id = ['a','b','c'] >>> pd.Series( ls, index = id ) a 1 b 2 c 3 dtype: int64 #DataFrameの場合(列名に'x'がつく) >>> pd.DataFrame( ls, index = id ,columns=['x'] ) x a 1 b 2 c 3
#Seriesの場合(転置しても変わらない) >>> ser = pd.Series( ls ) >>> ser.T #.Tは転置をとる a 1 b 2 c 3 #DataFrameの場合(転置すると行と列が入れ替わる) >>> df = pd.DataFrame( ls ) >>> df.T a b c x 1 2 3
2.1.pandasの構造取得
次のDataFrameとSeriesを例にとって説明します。>>> df 整数 数値 文字列 a 1 1.0 v b 2 2.0 w c 3 3.0 x d 4 4.0 y e 5 5.0 z >>> ser a 1 b 2 c 3 dtype: int64
(1)配列のタイプを取得する。
Pythonのtypeコマンドをdf、serに使うと、pandasのDataFrame、Seriesであることを確認できます。
type( ** )
>>> type(df) <class 'pandas.core.frame.DataFrame'> >>> type(ser) <class 'pandas.core.series.Series'>
type( **.index ) または type( **.columns )
>>> type(df.columns) <class 'pandas.core.indexes.base.Index'> >>> type(df.index) <class 'pandas.core.indexes.base.Index'> >>> type(ser.index) <class 'pandas.core.indexes.base.Index'>
このとき、DataFrameについては、各列ごとの型を出力します。
**.dtypes
>>> df.dtypes
整数 int64
数値 float64
文字列 object
dtype: object
>>> ser.dtypes
dtype('int64')
(2)配列のサイズを取得する。
a).shapeを使うDataFrameなら(行数、列数)を、Seriesなら(配列数、)を返します。
**.shape
>>> df.shape (5, 3) >>> ser.shape (3,)
DataFrameなら行数を、Seriesなら配列数を返します。
len( ** )
>>> len(df) 5 >>> len(ser) 3
(3)配列の詳しい情報を取得する。
df.info()
>>> df.info() <class 'pandas.core.frame.DataFrame'> Index: 5 entries, a to e Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 整数 5 non-null int64 1 数値 5 non-null float64 2 文字列 5 non-null object dtypes: float64(1), int64(1), object(1) memory usage: 160.0+ bytes
len( ** )
>>> ser.info() Traceback (most recent call last): File "<stdin>", line 1, in <module> ***** 省略 ***** AttributeError: 'Series' object has no attribute 'info'


