pandasの使い方
ライブラリの使い方
>
Python
- 1.pandasを動かしてみる
- 2.pandasのデータ構造
- 2.1.pandasの構造取得
- 2.2.Seriesの構造と作成
- 2.3.DataFrameの構造と作成
2.4.dataの操作
2.5.indexの操作
2.6.columunsの操作
3.データの読み書き
1.pandasを動かしてみる
pandasを動かすには、Numpyとpandasをインストールする必要があります。インストール方法はPythonインストールページを参照ください。
pandasを動かす方法として次の二つがあります。
- コマンドプロンプト上で直接入力
- ファイル内にコマンドを記述してファイル実行
そこで次のpandas_sample1.zipをダウンロードし、Desktop上に解凍しておきます。
(1)コマンドプロンプトの起動
コマンドプロンプトを立ち上げ、desktop上のpandas_sampleをカレントディレクトリに設定します。 ディレクトリの移動コマンドは“cd”です。
Microsoft Windows [Version 10.0.18362.836] (c) 2019 Microsoft Corporation. All rights reserved. C:\Users\***> cd desktop C:\Users\***\Desktop > cd pandas_sample C:\Users\***\Desktop\pandas_sample >
(2)pythonの起動
"python"と入力してEnterを押すと、pythonが起動します。C:\Users\***\Desktop\pandas_sample > python Python *.*.* (tags/v*.*.*:e********e, Jul * ****, **:**:**) [MSC v.**** 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
(3)pandas(+numpy)の起動
次のコマンドを入力すると、pandasを利用できます。>>> import numpy as np >>> import pandas as pd
(4)csvデータの読み込み
大量データの処理を行いたい場合にpandasを使うことが多いため、まずはcsvファイルからデータを取り込んでみます。 そこで、pandas_sampleフォルダ内にあるsample1_1.csvを読み込みます。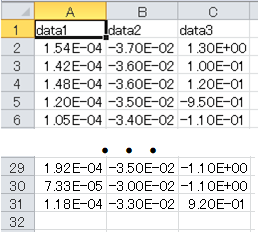
>>> df = pd.read_csv( 'sample1_1.csv' )
>>> df data1 data2 data3 0 0.000154 -0.037 1.300 1 0.000142 -0.036 0.100 2 0.000148 -0.036 0.120 ・・・(省略)・・・ 29 0.000118 -0.033 0.920 >>>
(5)indexの修正
左列の連番(index)を、1から始まる数列に置き換えてみます。まずは1~30までの数列を作り、変数IDに入れ込みます。
>>> ID = np.arange(1,31,1) >>> ID array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30]) >>>
>>> df.set_index( ID, inplace = True ) >>> df data1 data2 data3 1 0.000154 -0.037 1.300 2 0.000142 -0.036 0.100 3 0.000148 -0.036 0.120 ・・・(省略)・・・ 30 0.000118 -0.033 0.920 >>>
(6)行データの抽出
"10行目"のデータを抽出します。>>> df.loc[10] data1 0.000144 data2 -0.035000 data3 -0.150000 Name: 10, dtype: float64 >>>
(7)列データの抽出
data2の列データを抽出します。>>> df[ 'data2' ] 0 -0.037 1 -0.036 ・・・(省略)・・・ 29 -0.033 Name: data2, dtype: float64 >>>
(8)要素データの抽出
(3行, data3列)データを抽出します。>>> df.loc[ 3 , 'data3' ] 0.12 >>>
(9)データの計算
a)すべてのデータに1を加える場合、df + 1と入力すれば事足ります。>>> df data1 data2 data3 1 0.000154 -0.037 1.300 2 0.000142 -0.036 0.100 ・・・(省略)・・・ 30 0.000118 -0.033 0.920 >>> >>> df + 1 data1 data2 data3 1 1.000154 0.963 2.300 2 1.000142 0.964 1.100 ・・・(省略)・・・ 30 1.000118 0.967 1.920 >>>
>>> df data1 data2 data3 1 0.000154 -0.037 1.300 2 0.000142 -0.036 0.100 ・・・(省略)・・・ 30 0.000118 -0.033 0.920 >>> >>> df['data2'] = df['data2'] / 100 >>> df data1 data2 data3 1 0.000154 -0.00037 1.300 2 0.000142 -0.00036 0.100 ・・・(省略)・・・ 30 0.000118 -0.00033 0.920 >>>
>>> df data1 data2 data3 1 0.000154 -0.037 1.300 ・・・ >>> df.loc[1].mean() 0.43326133333333333 >>>
>>> df['data3'].sum() -7.164999999999999 >>>
>>> df data1 data2 data3 0 0.000154 -0.037 1.300 1 0.000142 -0.036 0.100 2 0.000148 -0.036 0.120 ・・・ >>> df2 data1 data2 data3 0 0.000308 -0.074 2.600 1 0.000284 -0.072 0.200 2 0.000296 -0.072 0.240 ・・・ >>> df + df2 data1 data2 data3 0 0.000462 -0.111 3.900 1 0.000426 -0.108 0.300 2 0.000444 -0.108 0.360 ・・・
ここでは、実際にpandasをさわってみて、使えそうなことを体感してもらうことが目的でした。
pandasは、データ分析や機械学習を行う上で必要な機能(ライブラリ)が備わっています。 これらを活用することで、より簡単に、より効率的にデータ操作を行うことができます。 データ分析では、データの操作や関数の作成などのプログラミングに多くの時間を必要とします。 これらに対して割く時間をpandasは大幅に軽減できます。 また、プログラミングの負担が軽くなることから、高度なデータ分析、例えば機械学習なども“とりあえずやってみよう”、というレベルから始められます。
ただし、pandasを使うためには、それなりのルールに従わなくてはなりません。 その点については慣れが必要です。


