3.Pandasによるファイル読込・出力
Pandasのファイル読込・出力に関する詳しい内容は、Pandasマニュアルを参照ください。3.1.csvファイルの読み込み
Pandasにはcsvファイルの読み込みコマンドとして“read_csv()”が準備されており、Pandasの“データフレーム形式”(下記参照)でファイルの中身を出力します。 一行目は“ヘッダ部”、一列目は“データindex部”になります。X1 X2 X3 X4 X5 X6 X7 X8 0 0.003 -0.037 1.300 -17.0 0.000154 282.0 0.0019 300.0 1 0.003 -0.036 0.100 -17.0 0.000142 281.0 0.0024 300.0 2 0.003 -0.036 0.120 -17.0 0.000148 281.0 0.0170 300.0 ・・・ 27 0.003 -0.035 -1.100 -18.0 0.000192 287.0 0.0770 300.0 28 0.003 -0.030 -1.100 -13.0 0.000073 268.0 0.2800 300.0 29 0.003 -0.033 0.920 -16.0 0.000118 278.0 0.1300 300.0
3.1.1.簡単な読み込み
下図のようなデータ形式のcsvファイルを読み込む場合のサンプルコードです。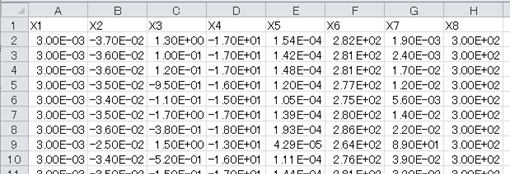
図3_1_1 sample3_1.csv
import pandas as pd getFN='sample3_1_1.csv' readData=pd.read_csv(getFN) print (readData)
“read_csv”の引数はファイルパスのみです。 取得結果は以下の通りです。csvファイルの一行目が自動的にヘッダとして認識され、一列目のデータindex部が自動で追加されます。
X1 X2 X3 X4 X5 X6 X7 X8 0 0.003 -0.037 1.300 -17.0 0.000154 282.0 0.0019 300.0 1 0.003 -0.036 0.100 -17.0 0.000142 281.0 0.0024 300.0 2 0.003 -0.036 0.120 -17.0 0.000148 281.0 0.0170 300.0 ・・・ 27 0.003 -0.035 -1.100 -18.0 0.000192 287.0 0.0770 300.0 28 0.003 -0.030 -1.100 -13.0 0.000073 268.0 0.2800 300.0 29 0.003 -0.033 0.920 -16.0 0.000118 278.0 0.1300 300.0
3.1.2.ヘッダやデータ型などの扱い
(1)半角英数字のみの場合
下図のようなデータ形式のcsvファイルを読み込むにあたって、下記2点を行ったうえでファイルの中身を取得します。
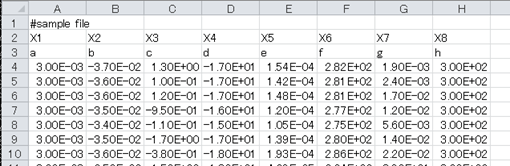
図3-1-2-1 sample3_1_2_1.csv
- #はコメント行として取得しない
- 2、3行目はヘッダ部として扱う
サンプルコードは以下になります。
import pandas as pd getFN='sample3_1_2_1.csv' #引数にcomment,header追加 readData=pd.read_csv(getFN,comment='#',header=[0,1]) print (readData)
| 引数 | 指定内容 |
|---|---|
| comment | 指定した一文字(今回は'#')から始まる文字列を無視します。 |
| header | 指定した行番号をヘッダとして扱います。commentで無視された行は除外してカウントします。 一行のみ:header=0、複数行:header=[0,1] |
X1 X2 X3 X4 X5 X6 X7 X8 a b c d e f g h 0 0.003 -0.037 1.300 -17.0 0.000154 282.0 0.0019 300.0 1 0.003 -0.036 0.100 -17.0 0.000142 281.0 0.0024 300.0 2 0.003 -0.036 0.120 -17.0 0.000148 281.0 0.0170 300.0 ・・・ 27 0.003 -0.035 -1.100 -18.0 0.000192 287.0 0.0770 300.0 28 0.003 -0.030 -1.100 -13.0 0.000073 268.0 0.2800 300.0 29 0.003 -0.033 0.920 -16.0 0.000118 278.0 0.1300 300.0
(2)日本語が含まれる場合
下図のように日本語が含まれる場合は、エンコーディングが必要になります。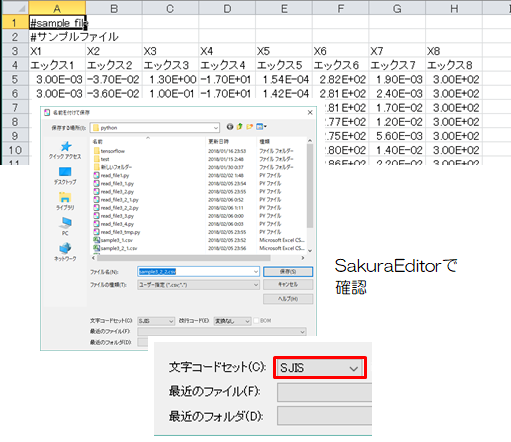
図3-1-2-2 sample3_1_2_2.csv
import pandas as pd getFN='sample3_1_2_2.csv' #引数にencodingを追加 readData=pd.read_csv(getFN,comment='#',header=[0,1],encoding='shift_jis') print (readData)
X1 X2 X3 X4 X5 X6 X7 X8 エックス1 エックス2 エックス3 エックス4 エックス5 エックス6 エックス7 エックス8 0 0.003 -0.037 1.300 -17.0 0.000154 282.0 0.0019 300.0 1 0.003 -0.036 0.100 -17.0 0.000142 281.0 0.0024 300.0 2 0.003 -0.036 0.120 -17.0 0.000148 281.0 0.0170 300.0 ・・・ 27 0.003 -0.035 -1.100 -18.0 0.000192 287.0 0.0770 300.0 28 0.003 -0.030 -1.100 -13.0 0.000073 268.0 0.2800 300.0 29 0.003 -0.033 0.920 -16.0 0.000118 278.0 0.1300 300.0
(3)列ごとにデータ型を指定する場合
例として、列X4、X6、X8をint型とし、それ以外はfloat型とします。
import pandas as pd
getFN='sample3_1_2_1.csv'
#引数にdtypeを追加
readData=pd.read_csv(getFN,comment='#',header=[0,1],dtype={'X4':int,'X6':int,'X8':int})
#readData=pd.read_csv(getFN,comment='#',header=[0,1],dtype={3:int,5:int,7:int})
print (readData)
{“列番号または列ヘッダ”:型,“列番号または列ヘッダ”:型,・・・}
です。データ型の詳細はNumpy Manualを参照ください。 取得結果は以下の通りで、X4、X6、X8がint型に変わっているのが分かります。
X1 X2 X3 X4 X5 X6 X7 X8 a b c d e f g h 0 0.003 -0.037 1.300 -17 0.000154 282 0.0019 300 1 0.003 -0.036 0.100 -17 0.000142 281 0.0024 300 2 0.003 -0.036 0.120 -17 0.000148 281 0.0170 300 ・・・ 27 0.003 -0.035 -1.100 -18 0.000192 287 0.0770 300 28 0.003 -0.030 -1.100 -13 0.000073 268 0.2800 300 29 0.003 -0.033 0.920 -16 0.000118 278 0.1300 300
3.1.3.行・列調整
取得データ行や列の調整を行うことで、不必要なデータのカット、必要なデータのみ取得が行えます。 サンプルコードは以下の通りです。import pandas as pd getFN='sample3_1_1.csv' readData=pd.read_csv(getFN,skiprows=[1,2,5],nrows=5,usecols=['X1','X2','X4']) #readData=pd.read_csv(getFN,skiprows=[1,2,5],nrows=5,usecols=[0,1,3]) print (readData)
| 引数 | 指定方法 |
|---|---|
| skiprows | 指定した行を飛ばして取得します。1行目=0、2行目=1、・・・で指定します。 |
| nrows | 指定した行数分取得します。ヘッダ行数分を除いて、指定した行数取得します。 |
| usecols | 指定した列を取得します。ヘッダ名または列番号で指定します(['X1','X2','X4']または[0,1,3])。列番号の場合は1列目=0、2列目=1、・・・で指定します。 |
X1 X2 X4 0 0.003 -0.036 -17.0 1 0.003 -0.035 -16.0 2 0.003 -0.035 -17.0 3 0.003 -0.036 -18.0 4 0.003 -0.025 -13.0
3.2.csvファイル出力
Pandasにはデータフレーム形式でのcsvファイル出力コマンドとして“DataFrame.to_csv()”が準備されています。(1)簡単な出力
例として、sample3_1_1.csvの1、2列目を取得して、output.csvに出力するサンプルを示します。
import pandas as pd
getFN='sample3_1_1.csv'
readData=pd.read_csv(getFN,usecols=[0,1])
#csvファイルへ出力
readData.to_csv("output1.csv")
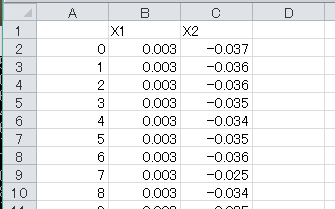
図3-2-1 output1.csv
Pandasの出力フォーマットに合わせて、一行目にヘッダが記述され、一列目にデータindexが追加されています。(2)ヘッダやindexを出力しない場合
ヘッダ部やindexが不要な場合のサンプルコードは以下になります。
import pandas as pd
getFN='sample3_1_1.csv'
readData=pd.read_csv(getFN,usecols=[0,1])
#引数にindex,header追加
readData.to_csv("output2.csv",index=False,header=False)
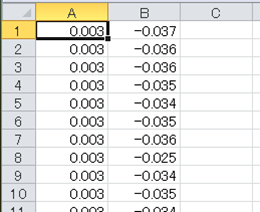
図3-2-2 output2.csv
(3)ファイルに追記する場合
すでにあるcsvファイルに追記する場合は、“mode='a'”を引数に加えます。
import pandas as pd
getFN='sample3_1_1.csv'
readData=pd.read_csv(getFN,usecols=[0,1])
#csvファイルへ出力
readData.to_csv("output3.csv",index=False,header=False)
#追記:引数にmode追加
readData.to_csv("output3.csv",index=False,mode='a')
(4)日本語が含まれる場合
read_csv同様、日本語が含まれる場合はエンコーディングが必要になります。
import pandas as pd
getFN='sample3_1_2_2.csv'
readData=pd.read_csv(getFN,comment='#',header=[0,1],encoding='shift_jis')
print (readData)
#引数にencoding追加
readData.to_csv("output4.csv",index=False,encoding='shift_jis')
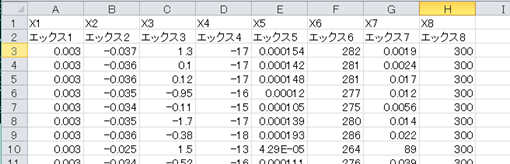
図3-2-4 output4.csv


