2.Numpyによるファイル読込・出力
Numpyでcsvやtsvファイル(構造化されたテキストファイル)の読み込み・出力は可能ですが、データの並びが矩形(行/列)であることが条件のようです。 Numpyではファイル読込・出力コマンドに以下を用います。-
loadtxt:
ファイル読込用。
データ内に欠損(空白)があるとエラーになります
-
genfromtxt:
ファイル読込用。
データ欠損部は指定値で埋められます。
-
savetxt:
ファイル保存用。
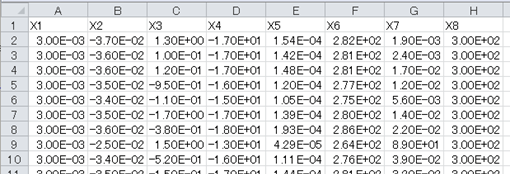
図2-1 sample2.csv
2.1.数値データのみを扱う場合
まずはサンプルコードを示します。import numpy as np getFN='sample2.csv' readData=np.genfromtxt(getFN,delimiter=',',skip_header=1,usecols=(0,1,5)) print (readData)
| 引数 | 指定方法 |
|---|---|
| 読込ファイル名 (変数“getFN”) |
実行ディレクトリにそのファイルがある場合はファイル名のみか、./ファイル名を指定します。 別のディレクトリにファイルがある場合は、絶対パス、相対パスのどちらでも構いません。 |
| delimiter | delimiterはデータ分割に使用する記号を指定します。 csvはカンマ(,)区切りなのでdelimiter=','と指定します。 タブ区切りの場合はdelimiter='\t'と指定します。 |
| skip_header | ヘッダーとして扱い、データ取得時に先頭行からSkipする行数を指定します。 |
| usecols | 抽出する列を指定できます。列番号は0から開始します。 サンプルコードの場合、1,2,6列目のデータを取得することになります。 また、連番で指定する場合はusecols=(range(1,3))とします。 |
[[ 3.00000000e-03 -3.70000000e-02 2.82000000e+02] [ 3.00000000e-03 -3.60000000e-02 2.81000000e+02] [ 3.00000000e-03 -3.60000000e-02 2.81000000e+02] [ 3.00000000e-03 -3.50000000e-02 2.77000000e+02] [ 3.00000000e-03 -3.40000000e-02 2.75000000e+02]
2.2.テキストデータを扱う場合
sample2.csvは一行目が文字列(ヘッダ部)、二行目以降が数値データになっていますが、この節では二行目以降も文字列である、として扱います。まずはサンプルコードを示します。
import numpy as np getFN='sample2.csv' readData=np.genfromtxt(getFN,delimiter=',',dtype='U') print (readData)
| 引数 | 指定方法 |
|---|---|
| dtype | データ型を指定します。 文字列として取得する場合は'U'(Unicode string)を指定します。 その他、'f'は浮動小数点型、'c'は複素数の浮動小数点型になります。 指定省略時は'f'が適用されます。 dtype=Noneを指定すると、データ列ごとにNumpy側が勝手に型を指定します。 データ型の詳細はNumpy Manualを参照ください。 |
サンプルコードを実行すると以下のように表示されます。 数値データとは異なり、各要素が''でくくられて出力されます。
[['X1' 'X2' 'X3' 'X4' 'X5' 'X6' 'X7' 'X8'] ['3.00E-03' '-3.70E-02' '1.30E+00' '-1.70E+01' '1.54E-04' '2.82E+02' '1.90E-03' '3.00E+02'] ['3.00E-03' '-3.60E-02' '1.00E-01' '-1.70E+01' '1.42E-04' '2.81E+02' '2.40E-03' '3.00E+02'] ['3.00E-03' '-3.60E-02' '1.20E-01' '-1.70E+01' '1.48E-04' '2.81E+02' '1.70E-02' '3.00E+02']
2.3.数値とテキストデータを扱う場合
今回は文字列部の一行目(ヘッダ部分)を文字列として、二行目以降を数値として取得することを目指します。 まずは2.1節の方法でデータを取得してみます。import numpy as np getFN='sample2.csv' readData=np.genfromtxt(getFN,delimiter=',') print (readData)
[[ nan nan nan nan nan nan nan nan] [ 3.00000003e-03 -3.70000005e-02 1.29999995e+00 -1.70000000e+01 1.53999994e-04 2.82000000e+02 1.90000003e-03 3.00000000e+02] [ 3.00000003e-03 -3.59999985e-02 1.00000001e-01 -1.70000000e+01 1.42000004e-04 2.81000000e+02 2.40000011e-03 3.00000000e+02] [ 3.00000003e-03 -3.59999985e-02 1.19999997e-01 -1.70000000e+01 1.48000006e-04 2.81000000e+02 1.70000009e-02 3.00000000e+02]
そこで、いったん文字列としてデータを取得し(2.2節の方法)、ヘッダ部と数値部を別々の配列にあてがいます。 その後、数値部分だけを型変更する手順でデータ取得を行います。
手順に合わせたサンプルコードを示します。
import numpy as np
#文字列としてデータ取得
getFN='sample2.csv'
readData=np.genfromtxt(getFN,delimiter=',',dtype='U')
#title行だけ抜き出す
title=readData[0]
#title行を削除
readData=np.delete(readData,0,0)
#数値部をfloat型に変更
readData=readData.astype('f')
print (title)
print (readData)


