文字列を操作する
全角・半角に変換する
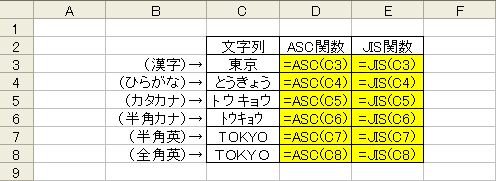
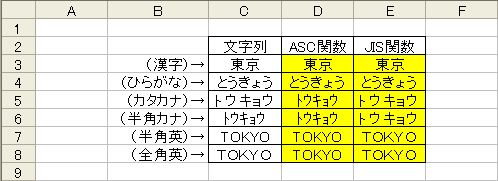
=ASC(文字列)
ASC関数は引数で指定したデータを半角に変換します。半角に変換できないデータ(ひらがなや漢字)は変換されずにそのまま返ります。
=JIS(文字列)
JIS関数はその逆で、引数に指定したデータを全角に変換します。半角変換できない漢字、ひらがなは無視されています。
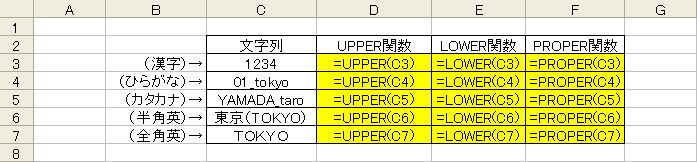
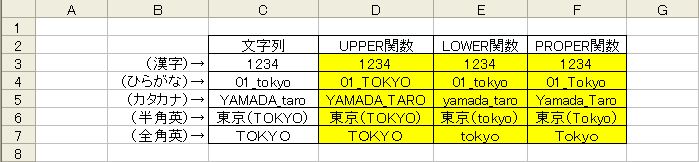
大文字・小文字に変換する
- =UPPER(文字列)
- =LOWER(文字列)
- =PROPER(文字列)
LOWER関数はその逆で、引数に指定したデータを小文字に変換します。
PROPER関数は、引数に指定したデータを先頭だけ大文字、他は小文字に変換します。
3つの関数の引数で、小文字に変換できないデータ(ひらがな・カタカナ・漢字)は変換されずにそのまま返ります。
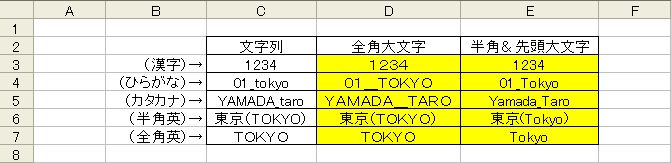
 ASC関数やJIS関数と組み合わせれば、一度に全角大文字・半角小文字などに変換できます。
ASC関数やJIS関数と組み合わせれば、一度に全角大文字・半角小文字などに変換できます。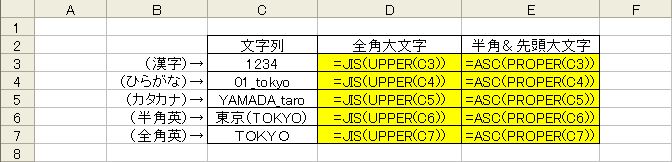
文字を取得する
- =LEFT(文字列,[文字数])
- =RIGHT(文字列,[文字数])
- =MID(文字列,開始位置,文字数)
RIGHT関数は引数の右端からの指定文字数を取得します。
LEFT関数、RIGHT関数の文字数を省略した場合は1文字だけ取得できます。
MID関数は引数の”開始位置番目”の文字から”指定文字数”を取得します。
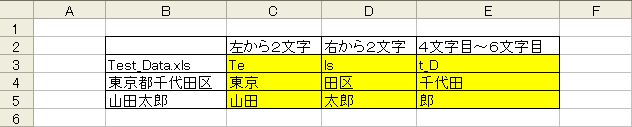
例)”Test_Data.xls”という文字列から
(1)”Test”だけを取得する場合
=LEFT(”Test_Data.xls”,4)
(2)”.xls”だけを抜き取る場合
=RIGHT(”Test_Data.xls”,4)
(3)”Data”という文字列を抜き取る場合
=MID(”Test_Data.xls”,6,4)

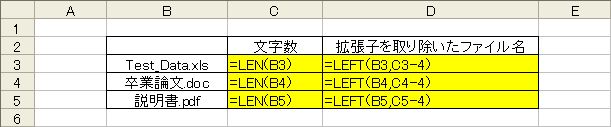
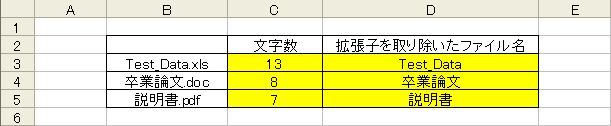
文字数を取得する
=LEN(文字列)
LEN関数は引数で指定した文字数を数値で返します。以下の例では拡張子を取り除いたファイル名だけを取り出します。
(拡張子の文字数は”.xls”など4文字のみと仮定)
LEFT関数で左から取得する文字数は、(全文字数 - 拡張子文字数)となります。
文字を検索する
- =FIND(検索文字列,対象,開始位置)
- =SEARCH(検索文字列,対象,開始位置)
それに対しSEARCH関数は大文字と小文字を同一文字として扱い、更にワイルドカード検索ができます。
戻り値は、検索した文字が左端から何文字目に位置するかという数値です。
以下の例では文字列から”.xls”という「半角小文字」の拡張子を検索しています。

 FIND関数は全角小文字でも半角大文字でも検索できずエラーになっているのに対し、
SEARCH関数は半角大文字でも検索に引っ掛かっていることがわかります。
FIND関数は全角小文字でも半角大文字でも検索できずエラーになっているのに対し、
SEARCH関数は半角大文字でも検索に引っ掛かっていることがわかります。
次は応用例です。
ファイル名の”_”(アンダーバー)以降の名前部分を抜き出します。
- FIND関数でアンダーバーが何文字目に位置するか検索
- LEN関数で全体の文字数を取得後、①の値と拡張子(4文字)を引いて名前の文字数を計算
- 名前部分をMID関数で取得


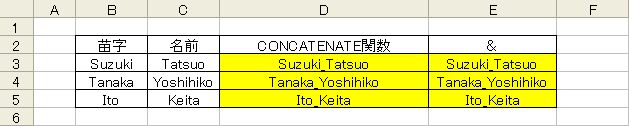
文字を結合する
- =CONCATENATE(文字列1,文字列2,・・・,文字列30)
- =(文字列1)&(文字列2)&・・・ ※演算子の&(アンド)
演算子の”&”も全く同じですが、データの間に全て”&”を入れる必要があります。
結合する個数が多いときはCONCATENATE関数を使うほうが楽でしょう。
以下の例では苗字と名前の間に”_”(アンダーバー)を入れて文字を結合しています。

文字を置換する
- =SUBSTITUTE(文字列,検索文字列,置換文字列,[置換対象番目])
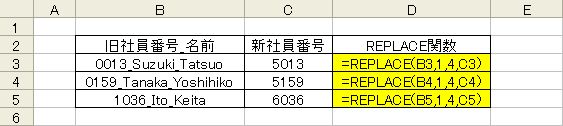
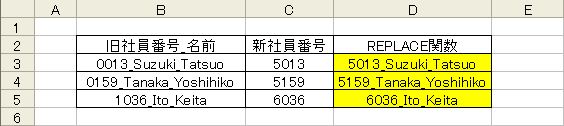
- =REPLACE(文字列,開始位置,文字数,置換文字列)
SUBSTITUTE関数は文字列を検索しつつ置換することが可能ですが、 REPLACE関数は決まった開始位置・文字数を置換するため、 検索と置換を一度に行いたい場合はSUBSTITUTE関数の方が使いやすいです。
以下の例では”_”(アンダーバー)を半角スペースに置換しています。
アンダーバーの位置は不定であり、REPLACE関数を使用する場合はFIND関数を使用する必要があります。

 次の例では社員番号と名前の組み合わさっている文字列から社員番号を置換します。
次の例では社員番号と名前の組み合わさっている文字列から社員番号を置換します。社員番号は個人ごとに異なり、SUBSTITUTE関数で検索できないため、REPLACE関数を使用します。